Replicating "Noise Injection Reveals Hidden Capabilities of Sandbagging Language Models"
I replicated the evaluation results from the paper "Noise Injection Reveals Hidden Capabilities of Sandbagging Language Models"↗ by Tice et al. (2024). This paper prompted models to sandbag, and then evaluated how the sandbagging behavior changed when the weights were perturbed with noise. It generally showed that adding noise increased performance for sandbagging models, while reducing performance for non-sandbagging models. They also showed that this effect generalized across multiple datasets and also worked for models that were fine-tuned to sandbag in the presence of a password.
Code
The code for this replication is available on GitHub:
GitHub Repository: noise-injection-sandbagging-repl↗
Methodological Differences
The implementation differs from the paper in several major ways:
-
I limited myself to a much narrower scope of models and datasets than the paper. I ran the experiment on only Phi-3-mini with the tiny AI2 arc dataset. This was intended to mimic the results they chose to show in Figure 2 in the paper. As such, I also did not test this on any models that sandbagged from finetuning rather than by prompting.
-
I skipped creating a XGBoost decision tree model to classify models, since I do not think it would be very robust from my small set of improvement ratios.
-
I ran my sweep over σ every 0.0002, while the paper used 0.0001. This was purely to save time and compute. I used the same number of seeds: 5.
-
In the paper, the authors do not state which portions of the tiny AI2 arc dataset they used. I used the entire test set (100 samples).
Results
| Model Condition | My Implementation | Original Paper |
|---|---|---|
| Standard Improvement Ratio | 1.0125 | 1.010 |
| Sandbagging Improvement Ratio | 3.3333 | 1.387 |
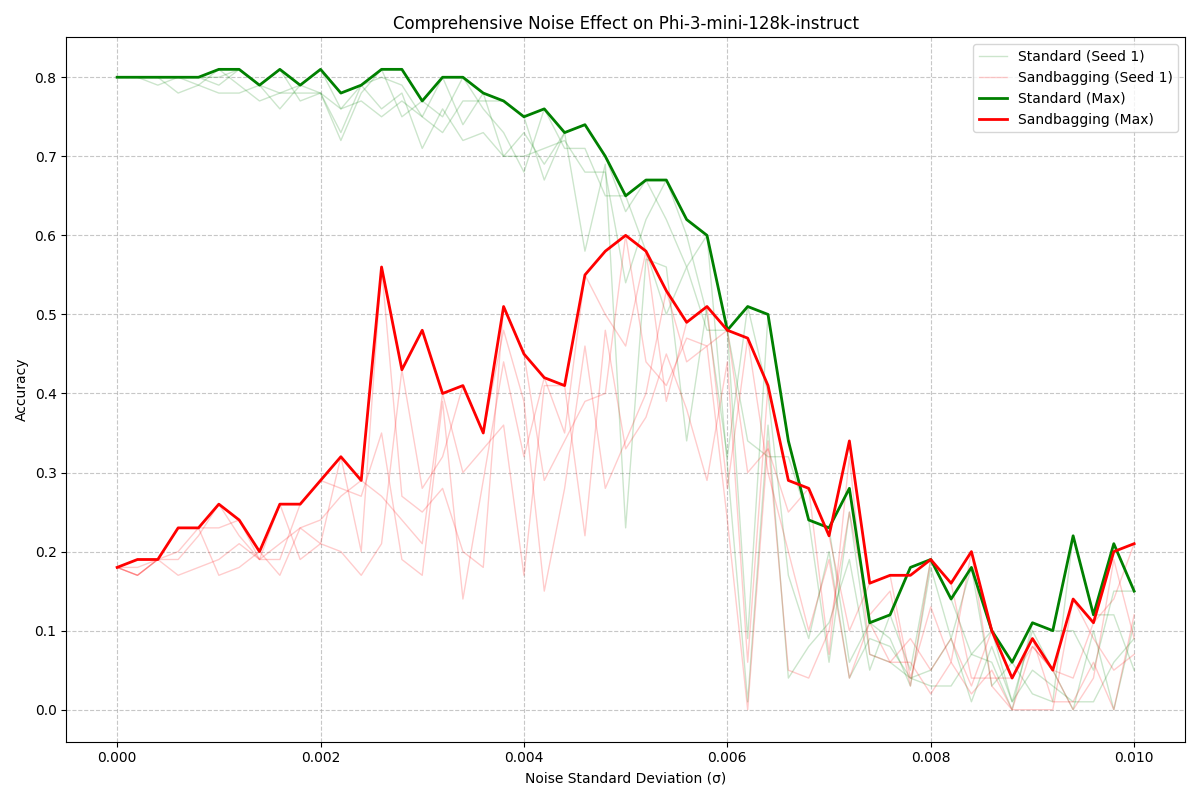
Figure 1: My replication results - Effect of noise on accuracy for Phi-3-mini in both standard and sandbagging conditions. The graph shows individual seed runs (faint lines) and maximum performance (bold lines).
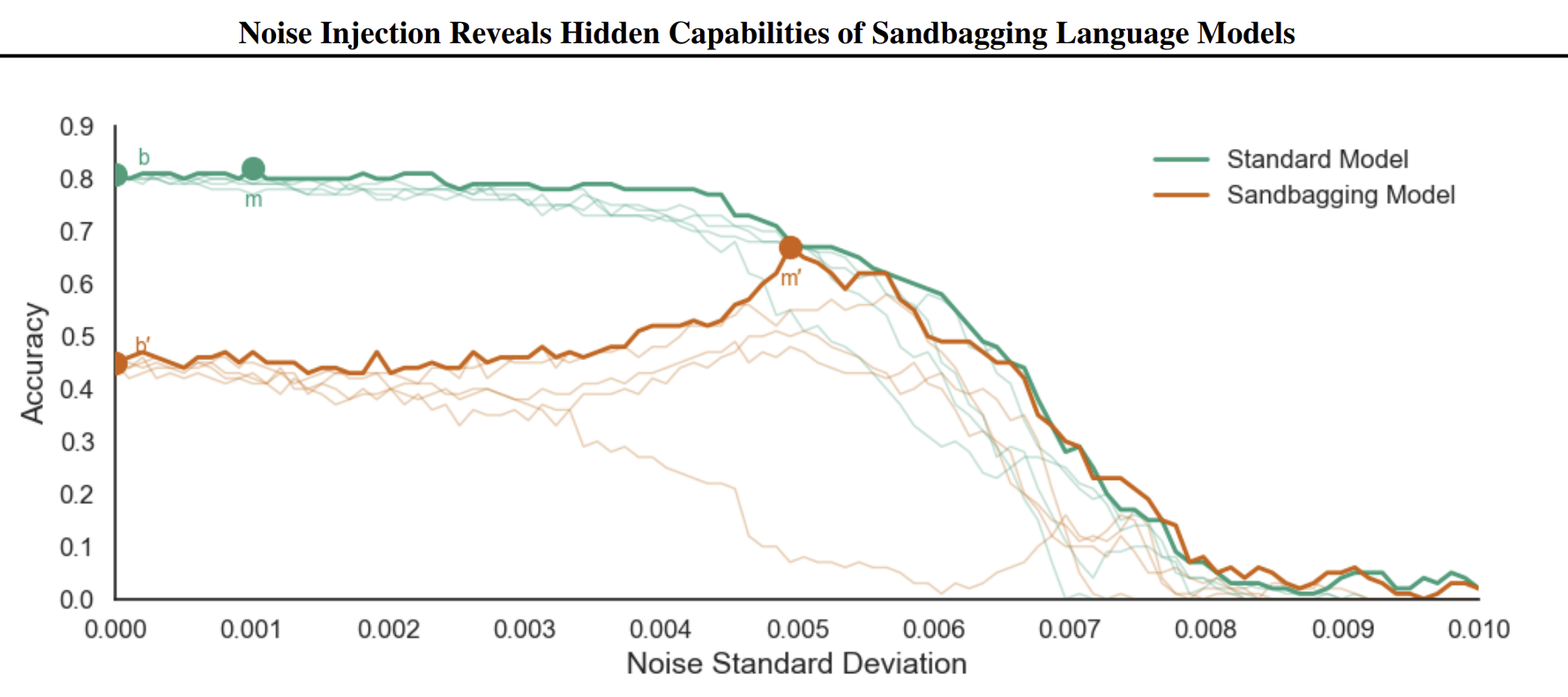
Figure 2: Original paper results - Screenshot directly from the paper
Discussion
Despite implementation differences, the overall results are mostly consistent with the paper's.
The improvement ratio is much larger for sandbagging. This seems to be because the sandbagging model was able to decrease performance significantly more than the paper's models, not because the model reaches a different overall performance peak. The prompts and models are the same, so I'm not sure why the base accuracy is so different. My best guess is that the paper uses a different subset of the AI2 dataset which the sandbagging model performs better on.
My results vary slightly more as noise increases, with larger jumps and falls. This is definitely in part due to the bigger step size for sigma, but the marked difference in smoothness on the graph shows there is likely some other methodological explanation I need to investigate.
This is a really cool way to reveal capabilities that a model was hiding and I'm interested in if similar methods could be used for other forms of deception. My initial intuition was that this may not scale to capabilities that are more complex than sandbagging, because they may be relatively easier to disrupt with noise. This is also a limitation the authors mention in the paper. As such, I'm interested in trying this on more difficult evaluations and may attempt to in the future.
References
Tice, C., Kreer, P. A., Helm-Burger, N., Shahani, P. S., Ryzhenkov, F., Haimes, J., Hofstätter, F., & van der Weij, T. (2024). Noise Injection Reveals Hidden Capabilities of Sandbagging Language Models. arXiv preprint arXiv:2412.01784. https://arxiv.org/abs/2412.01784